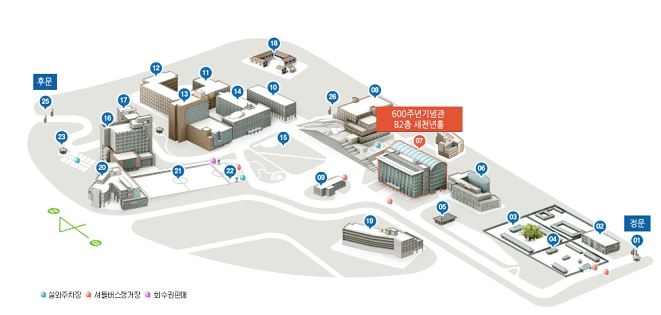
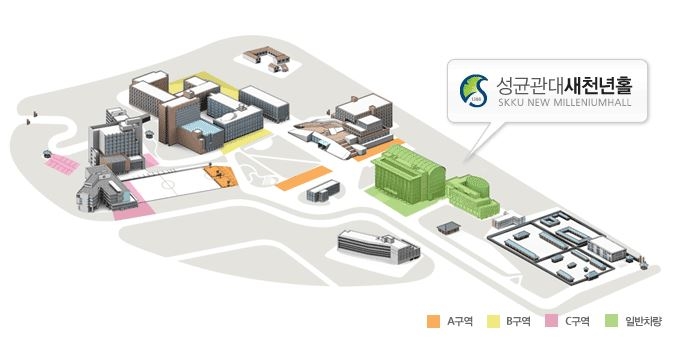
|
Day 1 (July 17, Tuesday) |
|
|
|
Time |
Presenter |
Title |
|
|
|
09:00 ~ 10:00 |
|
등록 (registration) |
|
|
S1 |
10:00 ~ 10:30 |
Prof. In So Kweon
(KAIST) |
Robust 3D vision in challenging conditions
|
|
|
S2 |
10:30 ~ 11:30 |
Prof. David Forsyth
(UIUC) |
Fooling detectors in various ways
|
|
|
Lunch (11:30 ~ 13:00) |
|
|
S3 |
13:00 ~ 13:30 |
Prof. Kyoung Mu Lee
(Seoul National University) |
V2V-PoseNet: Voxel-to-voxel prediction network for accurate 3D hand and human pose estimation from a single depth map
|
|
|
S4 |
13:30 ~ 14:30 |
Prof. Marc Pollefeys
(ETH Zurich) |
Always on 3D computer vision for mixed reality and beyond
|
|
|
S5 |
14:30 ~ 15:30 |
Prof. Ming-Hsuan Yang
(UC Merced) |
Learning to track and segment objects |
|
|
Coffee break (15:30 ~ 15:50) |
|
|
S6 |
15:50 ~ 16:50 |
Prof. Sven Dickinson
(Univ. of Toronto) |
The role of symmetry in human and computer vision
|
|
|
S7 |
16:50~ 17:50 |
Prof. Svetlana Lazebnik
(UIUC) |
Joint modeling of images and language
|
|
|
|
|
|
|
|
|
Day 2 (July 18, Wednesday) |
|
|
|
Time |
Presenter |
Title |
|
|
O1-1 |
09:30 ~ 10:00 |
곽수하 교수
(POSTECH) |
Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation / CVPR 2018 |
|
|
O1-2 |
10:00 ~ 10:30 |
김선주 교수
(연세대) |
Fast video object segmentation by reference-guided mask propagation / CVPR 2018 |
|
|
O1-3 |
10:30 ~ 11:00 |
이승용 교수
(POSTECH) |
Indoor semantic segmentation using RGB-D images / ICCV 2017
|
|
|
Coffee break (11:00 ~ 11:15) |
|
|
Opening remark and KCVS meeting (11:15 ~ 11:45) |
|
|
Lunch (11:45 ~ 13:00) |
|
|
Poster 1 (13:00 ~ 14:30) |
|
|
P1-1 |
안지운*, 곽수하 |
(O1-1) Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation / CVPR 2018 |
|
|
P1-2 |
박성진*, 홍기상, 이승용 |
(O1-3) RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation / ICCV2017 |
|
|
P1-3 |
이정균*, 예재원, 박민규, 윤국진 |
(O1-4) Joint layout estimation and global multi-view registration for indoor reconstruction / ICCV 2017 |
|
|
P1-4 |
김표진*, 김현진 |
(O1-5) Indoor RGB-D compass from a single line and plane / CVPR 2018 |
|
|
P1-5 |
윤재성*, 심재영 |
(O1-8) Reflection removal for large-scale 3D point clouds / CVPR 2018 |
|
|
P1-6 |
주동규*, 김도연, 김준모 |
(O1-9) Generating a fusion image: One's identity and another's shape / CVPR 2018 |
|
|
P1-7 |
김영진*, 김민정, 김건희 |
Memorization precedes generation: Learning unsupervised GANs with memory networks / ICLR 2018 |
|
|
P1-8 |
나세일*, 이상호, 김지성, 김건희 |
A read-write memory network for movie story understanding / ICCV 2017 |
|
|
P1-9 |
문종환, 서홍석, 정일채*, 한보형 |
MarioQA: Answering questions by watching gameplay videos / ICCV 2017 |
|
|
P1-10 |
송광모*, 명희수, 이경무 |
SeedNet: Automatic seed generation with deep reinforcement learning for robust interactive segmentation / CVPR 2018 |
|
|
P1-11 |
조영현*, 오승욱, 강재연, 김선주 |
Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation / CVPR 2018 |
|
|
P1-12 |
전석준*, 백승환, 김민혁 |
Enhancing the spatial resolution of stereo images using a parallax prior / CVPR 2018 |
|
|
P1-13 |
김대식*, 유영준, 김지수, 이상국, 곽노준 |
Dynamic graph generation network: Generating relational knowledge from diagrams / CVPR 2018 |
|
|
P1-14 |
박종찬*, 이준영, 유동근, 권인소 |
Distort-and-Recover: Color enhancement using deep reinforcement learning / CVPR 2018 |
|
|
P1-15 |
주경돈*, 오태현, 권인소, Jean-Charles Bazin |
Globally optimal inlier set maximization for atlanta frame estimation / CVPR 2018 |
|
|
P1-16 |
조동현*, 박진선, 오태현, Yu-Wing Tai, 권인소 |
Weakly and self supervised learning for content-aware deep image retargeting / ICCV 2017 |
|
|
P1-17 |
이석주, 김준식*, 윤재신, 신승학, Oleksandr Bailo, 김남일, 이태희, 홍현석, 한승훈, 권인소
|
VPGNet: Vanishing point guided network for lane and road marking detection and recognition / ICCV 2017
|
|
|
P1-18 |
박해솔*, 이경무 |
Joint estimation of camera pose, depth, deblurring, and super-resolution from a blurred image sequence / ICCV 2017
|
|
|
|
|
|
|
|
|
|
|
|
|
O1-4 |
14:30~ 15:00 |
윤국진 교수
(KAIST) |
Joint layout estimation and global multi-view registration for indoor reconstruction / ICCV 2017 |
|
|
O1-5 |
15:00~ 15:30 |
김현진 교수
(서울대) |
Robust visual odometry utilizing environmental structures / CVPR 2018 |
|
|
O1-6 |
15:30~ 16:00 |
김태균 교수
(ICL) |
3D hand pose estimation / CVPR 2018 |
|
|
Coffee break (16:00 ~ 16:15) |
|
|
O1-7 |
16:15~ 16:45 |
함범섭 교수
(연세대) |
Robust joint image filtering / TPAMI 2018 |
|
|
O1-8 |
16:45~ 17:15 |
심재영 교수
(UNIST) |
Reflection removal for large-scale 3D point clouds / CVPR 2018 |
|
|
O1-9 |
17:15~ 17:45 |
김준모 교수
(KAIST) |
Generating a fusion image: One's identity and another's shape / CVPR 2018 |
|
|
|
|
|
|
|
|
Day 3 (July 19, Thursday) |
|
|
|
Time |
Presenter |
Title |
|
|
O2-1 |
09:30 ~ 10:00 |
신진우 교수
(KAIST) |
Novelty detection under deep classifiers / ICLR 2018 and CVPR 2018 |
|
|
O2-2 |
10:00 ~ 10:30 |
김광인 교수
(Univ. of Bath) |
Combining multiple, heterogeneous task predictors / ICCV 2017 and CVPR 2018 |
|
|
Coffee break (10:30 ~ 10:45) |
|
|
O2-3 |
10:45~ 11:15 |
이용재 교수
(UC Davis) |
Cross-domain self-supervised multi-task feature learning using synthetic imagery / CVPR 2018 |
|
|
O2-4 |
11:15~ 11:45 |
장형진 교수
(Univ. of Birmingham) |
Context-aware deep feature compression for high-speed visual tracking / CVPR 2018 |
|
|
Lunch (11:45 ~ 13:00) |
|
|
Poster 2 (13:00 ~ 14:30) |
|
|
P2-1 |
최종원, 장형진*, Tobias Fischer, 윤상두, 이규왕, 정지엽, Yiannis Demiris, 최진영 |
(O2-4) Context-aware deep feature compression for high-speed visual tracking / CVPR 2018 |
|
|
P2-2 |
이광무*, Eduard Trulls, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, Pascal Fua
|
(O2-6) Learning correspondences with eigen-free eigen / CVPR 2018 |
|
|
P2-3 |
김승룡, 민동보*, Stephen Lin, 손광훈 |
(O2-7) DCTM: Discrete-continuous transform matching for semantic flow / ICCV 2017 |
|
|
P2-4 |
김은우*, 안찬호, 오성회 |
(O2-8) Nested sparse networks / CVPR 2018 |
|
|
P2-5 |
Shao-Hua Sun*, 노현우, Sriram Somasundaram, 임재환 |
(O2-9) Neural program synthesis from diverse demonstration videos / ICML 2018 |
|
|
P2-6 |
이해범*, 양은호, 황성주 |
(O2-10) Deep asymmetric multi-task feature learning / ICML 2018 |
|
|
P2-7 |
서홍석*, Andreas Lehrmann, 한보형, Leonid Sigal |
Visual reference resolution using attention memory for visual dialog / NIPS 2017 |
|
|
P2-8 |
문경식*, 장주용, 이경무 |
V2V-PoseNet: Voxel-to-voxel prediction network for accurate 3D hand and human pose estimation from a single depth map / CVPR 2018 |
|
|
P2-9 |
노준혁*, 이수찬, 김범수, 김건희 |
Improving occlusion and hard negative handling for single-stage pedestrian detectors / CVPR 2018 |
|
|
P2-10 |
이상호*, 성진영, 주영재, 김건희 |
A memory network approach for story-based temporal summarization of 360° videos / CVPR 2018 |
|
|
P2-11 |
김영원, 이창렬*, 조대용, 권용훈, 최혁재, 윤국진 |
Automatic content-aware projection for 360 videos / ICCV 2017 |
|
|
P2-12 |
유재영*, 이상호, 곽노준 |
Image restoration by estimating frequency distribution of local patches / CVPR 2018 |
|
|
P2-13 |
신창하*, 전해곤, 윤영진, 권인소, 김선주 |
EPINET: A fully-convolutional neural network for light field depth estimation by using epipolar geometry / CVPR 2018 |
|
|
P2-14 |
윤재신, Francois Rameau, 김준식*, 이석주, 신승학, 권인소 |
Pixel-level matching for video object segmentation using convolutional neural networks / ICCV 2017 |
|
|
P2-15 |
김다훈*, 조동현, 유동근, 권인소 |
Two-phase learning for weakly supervised object localization / ICCV 2017 |
|
|
P2-16 |
임성훈, 전해곤*, 권인소 |
Robust depth estimation from auto bracketed images / CVPR 2018 |
|
|
P2-17 |
Arda Senocak*, 오태현, 김준식, Ming-Hsuan Yang, 권인소 |
Learning to localize sound source in visual scenes / CVPR 2018 |
|
|
P2-18 |
오태현, 주경돈*, Neel Joshi, Baoyuan Wang, 권인소, Sing Bing Kang |
Personalized cinemagraphs using semantic understanding and collaborative learning / ICCV 2017 |
|
|
P2-19 |
김태현, 이경무*, Bernhard Schölkopf, Michael Hirsch
|
Online video deblurring via dynamic temporal blending network / ICCV 2017 |
|
|
|
|
|
|
|
|
|
|
|
|
O2-5 |
14:30 ~ 15:00 |
조민수 교수
(POSTECH) |
Learning semantic correspondence / ICCV 2017 |
|
|
O2-6 |
15:00~ 15:30 |
이광무 교수
(Univ. of Victoria) |
Learning correspondences with eigen-free eigen / CVPR 2018 |
|
|
O2-7 |
15:30~ 16:00 |
민동보 교수
(이화여대) |
DCTM: Discrete-continuous transform matching for semantic flow / ICCV 2017 |
|
|
Coffee break (16:00 ~ 16:15) |
|
|
O2-8 |
16:15~ 16:45 |
오성회 교수
(서울대) |
Nested sparse networks / CVPR 2018 |
|
|
O2-9 |
16:45~ 17:15 |
임재환 교수
(USC) |
Neural program synthesis from diverse demonstration videos / ICML 2018
|
|
|
O2-10 |
17:15~ 17:45 |
황성주 교수
(KAIST) |
Deep asymmetric multi-task feature learning / ICML 2018 |
|
|
Closing remark (17:45 ~ 18:00) |
|