KCCV 2016
초대의 글
KCCV2016 조직위원장
이화여대 전자공학과 교수 이 병 욱 배상
|

프로그램Day1 : 2016. 7. 21 (Thr)
Day2 : 2016. 7. 22 (Fri)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Semantic Segmentation and Object Detection from Images with Two Deep Configurations
연사: Prof. Jiaya Jia (CUHK)
Abstract
In high-level computer vision, semantic segmentation and object detection are important tasks. We introduce two methods that are published in this year CVPR to deal with them. Aiming at simultaneous detection and segmentation (SDS), we propose a proposal-free framework, which detect and segment object instances via mid-level patches. We design a unified trainable network on patches, which is followed by a fast and effective patch aggregation algorithm to infer object instances. Our method benefits from end-to-end training. Meanwhile, large-scale data is of crucial importance for learning semantic segmentation models. But annotating per-pixel masks is a tedious and inefficient procedure. We note that for the topic of interactive image segmentation, scribbles are very widely used in academic research and commercial software, and are recognized as one of the most userfriendly ways of interacting. We thus propose using scribbles to annotate images, and develop an algorithm to train convolutional networks for semantic segmentation supervised by scribbles.
Biography
Jiaya Jia is currently a professor in Department of Computer Science and Engineering, The Chinese University of Hong Kong (CUHK). He heads the research group focusing on computational photography, machine learning, practical optimization, and low- and high-level computer vision. He currently serves as an associate editor for the IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) and served as an area chair for several-year ICCV and CVPR. He was also on the technical paper program committees of SIGGRAPH, SIGGRAPH Asia, ICCP, and 3DV, and cochaired the Workshop on Interactive Computer Vision, in conjunction with ICCV 2007. He received the Young Researcher Award 2008 and Research Excellence Award 2009 from CUHK.
Deep SLAM?
연사: Prof. Ian Reid (University of Adelaide)
Abstract
Deep Learning has rapidly and irrevocably changed the way numerous tasks in computer vision are carried out. In particular it has opened the door to useful semantic interpretations of scenes. In this talk I will discuss ongoing work in my group in which we are using deep learning in the context Simultaneous Localisation and Mapping. I will discuss how we generate semantically useful segmentations of scenes, and how we estimate the depth of a scene from a single view, trained without supervision. I will show how we have incorporated some of these ideas into a real-time Dense SLAM system.
Biography
Ian Reid is a Professor of Computer Science and an ARC Australian Laureate Fellow at the University of Adelaide. Until 2012 he was a Professor of Engineering Science at the University of Oxford. He received a BSc in Computer Science and Mathematics with first class honours from University of Western Australia in 1987 and was awarded a Rhodes Scholarship in 1988 to study at the University of Oxford, where he obtained a D.Phil. in 1992 and stayed initially as a postdoctoral researcher, and latterly as a University Lecturer. His research interests include active vision, visual tracking, SLAM, human motion capture and intelligent visual surveillance, with an emphasis on real-time implementations whenever possible. He has published 170 papers and has an h-index of 52. His work won prizes at BMVC ’05, ’09, ’10, and CVPR ’08 and 3DV ’14. He serves on the program committees of various national and international conferences. He is also on the editorial board of IEEE T-PAMI and Computer Vision and Image Understanding.
Understanding Group Activities from Multiple Egocentric Videos
연사: Prof. Yoichi SATO (Univ. of Tokyo)
Abstract
In this talk, I will talk about our recent attempts on understanding group activities from multiple egocentric videos as a part of our project called Collective Visual Sensing for Analyzing Human Attention and Behavior. Unlike conventional videos, egocentric videos pose major challenges for various computer vision tasks due to severe motion blur caused by ego-motion and significantly varying viewpoints. To overcome such difficulties, we have been exploiting a novel approach of jointly analyzing multiple egocentric videos for solving different vision tasks. In particular, I will describe our three methods for identifying people in egocentric videos, discovering time intervals when multiple people attend to a common target jointly, and recognizing subtle actions and reactions during interaction.
Biography
Yoichi Sato is a professor at Institute of Industrial Science, the University of Tokyo. He received his B.S. degree from the University of Tokyo in 1990, and his MS and PhD degrees in robotics from School of Computer Science, Carnegie Mellon University in 1993 and 1997 respectively. His research interests include physics-based vision, reflectance analysis, image-based modeling and rendering, and gaze and gesture analysis. He served/is serving in several conference organization and journal editorial roles including IEEE Transactions on Pattern Analysis and Machine Intelligence, International Journal of Computer Vision, Computer Vision and Image Understanding, IET Computer Vision, IPSJ Journal of Computer Vision and Applications, ECCV 2012 Program Co-Chair, ACCV 2016 Program Co-Chair, and MVA 2013 General Chair.
Pose Estimation Demonstrations and Combined of Decision Forests/CNNs
연사: 김태균 교수 (Imperial College)
Abstract
This talk demonstrates our own developments in 3D pose estimation problems: 1) recovering 6D Object Pose in the Crowd, 2) Hierarchical Cascade Hand Pose Estimation. 6D object pose estimation in the crowd is challenging due to severe foreground occlusions, multi-instances, large scale changes, and highly cluttered backgrounds. Our method is a pipeline of part-based feature learning, discriminative classification and hough-voting, and active camera planning. Hand pose estimation brings unique challenges over body pose: the high degree of articulation and viewpoint changes, self-occlusions, fast motions, and size/shape variations. Our hybrid method combines discriminative regression and generative model-based verification in a hierarchical manner. The methodological details will only be briefed to support the demonstrations. To this end, we also talk about our recent research so called the combined of decision forests and convolutional neural networks. The novel solution takes the advantages of learning representation, conditional computing, efficiency, and cross modality deep learning.
Biography
Tae-Kyun (T-K) Kim is Associate Professor and the leader of Computer Vision and Learning Lab at Imperial College London, UK, since Nov 2010. He obtained his PhD from Univ. of Cambridge in 2008 and Junior Research Fellowship (governing body) of Sidney Sussex College, Univ. of Cambridge for 2007-2010. His research interests primarily lie in decision forests (tree-structure classifiers) and linear methods for: articulated hand pose estimation, face analysis and recognition by image sets and videos, 6D object pose estimation, active robot vision, activity recognition, object detectiontracking, which lead to novel active and interactive vision. He has co-authored over 40 academic papers in top-tier conferences and journals in the field, he is the general co-chair of HANDS workshop (in conjunction with CVPR15CVPR16), and Object Pose workshop (in conjunction with ICCV15ECCV16). He is Associate Editor of Image and Vision Computing Journal, and IPSJ Trans. on Computer Vision and Applications. He is the co-recipient of KUKA best service robotics paper award at ICRA 2014, and his co-authored algorithm for face image retrieval is an international standard of MPEG-7 ISOIEC.
Visual Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
연사: 한보형 교수 (POSTECH)
Abstract
I present a novel image question answering (ImageQA) algorithm by learning a convolutional neural network (CNN) with a dynamic parameter layer whose weights are determined adaptively based on questions. For the adaptive parameter prediction, our algorithm employs a separate parameter prediction net- work, which consists of gated recurrent unit (GRU) taking a question as its input and a fully-connected layer generating a set of candidate weights as its output. However, it is challenging to construct a parameter prediction network for a large number of parameters in the fully-connected dynamic parameter layer of the CNN. We reduce the complexity of this problem by incorporating a hashing technique, where the candidate weights given by the parameter pre- diction network are selected using a predefined hash function to determine individual weights in the dynamic parameter layer. The proposed network–joint network with the CNN for ImageQA and the parameter prediction network–is trained end-to-end through back-propagation, where its weights are initialized using a pre-trained CNN and GRU. The proposed algorithm illustrates the state-of-the-art performance on all available public ImageQA benchmarks.
Biography
Bohyung Han received the B.S. and M.S. degrees from the Department of Computer Engineering at Seoul National University, Korea, in 1997 and 2000, respectively, and the Ph.D. degree from the Department of Computer Science at the University of Maryland, College Park, MD, USA, in 2005. He is currently an Associate Professor with the Department of Computer Science and Engineering at POSTECH, Korea. He received NAVER Young Faculty Award in 2016 and won Visual Object Tracking Challenge in 2015. He has served or will be serving as an Area Chair in CVPR 2017, NIPS 2015, ICCV 2015, ACCV 201220142016, ACML 2016 and WACV 2014, and as a Demo Chair in ACCV 2014. He is also serving as Area Editor in Computer Vision and Image Understanding and Associate Editor in Machine Vision Applications. His current research interests include computer vision and machine learning with emphasis on deep learning.
Image and Video Segmentation
연사: 김창수 교수 (고려대)
Abstract
An unsupervised video object segmentation algorithm, which discovers a primary object in a video sequence automatically, is proposed in this work. We introduce three energies in terms of foreground and background probability distributions: Markov, spatiotemporal, and antagonistic energies. Then, we minimize a hybrid of the three energies to separate a primary object from its background. However, the hybrid energy is nonconvex. Therefore, we develop the alternate convex optimization (ACO) scheme, which decomposes the nonconvex optimization into two quadratic programs. Moreover, we propose the forward-backward strategy, which performs the segmentation sequentially from the first to the last frames and then vice versa, to exploit temporal correlations. Experimental results on extensive datasets demonstrate that the proposed ACO algorithm outperforms the state-of-the-art techniques significantly.
Biography
Chang-Su Kim received the Ph.D. degree in electrical engineering from Seoul National University with a Distinguished Dissertation Award in 2000. From 2000 to 2001, he was a Visiting Scholar with the Signal and Image Processing Institute, University of Southern California, Los Angeles. From 2001 to 2003, he coordinated the 3D Data Compression Group in National Research Laboratory for 3D Visual Information Processing in SNU. From 2003 and 2005, he was an Assistant Professor in the Department of Information Engineering, Chinese University of Hong Kong. In Sept. 2005, he joined the School of Electrical Engineering, Korea University, where he is now a Professor. His research topics include image processing and computer vision. In 2009, he received the IEEK/IEEE Joint Award for Young IT Engineer of the Year. In 2014, he received the Best Paper Award from Journal of Visual Communication and Image Representation (JVCI). He has published more than 230 technical papers in international journals and conferences. Dr. Kim is an Editorial Board Member of JVCI and an Associate Editor of IEEE Transactions on Image Processing.
Tracking and Identifying Multiple Objects across Multiple Cameras
연사: 윤국진 교수 (GIST)
Abstract
Visual object tracking is one of important research topics in computer vision and ranges from single object tracking in a single camera to multiple objects tracking in multiple cameras. While tracking a single object or multiple objects in a single camera has been intensively studied for last decades, tracking multiple objects across multiple cameras has recently come into the spotlight thanks to the advances in object detection and re-identification. However, many issues still remain to be solved for successful visual object tracking in general environments.
In this talk, I will introduce our recent tries to solve some fundamental problems in visual object tracking from single object tracking to multiple objects tracking in multiple cameras. Since the most important visual cues that can be used for visual tracking are the appearance and motion of an object, I fist propose the methods that model and fully exploit the appearance and the motion information of an object under severe pose variation, illumination change, occlusion, and camera motion. In addition, I propose to use pose information for object re-identification for multiple objects tracking across multiple cameras. I will also show some visual tracking demos based on the proposed methods.
Biography
Kuk-Jin Yoon received the B.S., M.S., and Ph.D. degrees in Electrical Engineering and Computer Science from Korea Advanced Institute of Science and Technology (KAIST) in 1998, 2000, 2006, respectively. He was a post-doctoral fellow in the PERCEPTION team in INRIA-Grenoble, France, for two years from 2006 to 2008, and joined the School of Electrical Engineering and Computer Science in Gwangju Institute of Science and Technology (GIST), Korea, as an assistant professor in 2008. He is currently an associate professor and a director of the Computer Vision Laboratory in GIST. His research interests include stereo, visual object tracking, SLAM, structure-from-motion, vision-based ADAS, etc.
Learning Local Features Through Deep Learning
연사: 이광무 박사 (EPFL)
Abstract
Local features are one of the core building blocks of Computer Vision, used in various tasks such as Image Retrieval, Visual Tracking, Image Registration, and Image Matching. There has been numerous works regarding the local feature pipeline, since the seminal work of Lowe in 2004. This includes the traditional hand crafted methods and the more recent ones based on Machine Learning.
In this talk, I will introduce learning based approaches to the local feature pipeline, and how to integrate them together into a fully learned pipeline through Deep Learning. I will first introduce ~, a learned local feature detector based on piece-wise linear regressor, that can provide highly repetitive keypoints. I will then introduce how to learn orientations of feature points through Deep Siamese Networks. I will then discuss how to put them together with recent Deep Descriptors. By leveraging Machine Learning techniques we achieve performances that significantly outperforms the state-of-the-art.
Biography
Kwang Moo Yi received his B.S. and Ph.D. degrees from the Department of Electrical Engineering and Computer Science of Seoul National University, Seoul, Korea, in 2007 and 2014, respectively. Currently, he is a Post-doctoral researcher in the Computer Vision Laboratory in Ecole Polytechnique Federale de Lausanne (EPFL). His research interests lie in various subjects in Computer Vision including, Learning Local Features, Deep Learning, Machine Learning, Visual Tracking, Augmented Reality, Motion Segmentation, Motion Detection, and so on.
A Holistic Approach to Cross-Channel Image Noise Modeling & Hyperspectral Imaging with Everyday Digital Cameras
연사: Seon Joo Kim (Assistant Professor, Dept. of Computer Science, Yonsei University)
Abstract
In this talk, I will present two independent works that are related to computational photography. First, I will show the influence of the in-camera imaging pipeline on noise and propose a new noise model in the 3D RGB space to accounts for the color channel mix-ups. A data-driven approach for determining the parameters of the new noise model is introduced as well as its application to image denoising. In the second part of the talk, I will introduce a framework for reconstructing hyperspectral images by using multiple consumer-level digital cameras. Our approach works by exploiting the different spectral sensitivities of different camera manufacturers and this allows hyperspectral imaging at a fraction of the cost of most existing hardwares.
Biography
Seon Joo Kim received the BS and MS degrees from Yonsei University, Seoul, Korea, in 1997 and 2001. He received the PhD degree in computer science from the University of North Carolina at Chapel Hill in 2008. He is currently an assistant professor in the Department of Computer Science, Yonsei University, Seoul, Korea. His research interests include computer vision, computer graphics/computational photography, and machine learning.
Depth map estimation from unusual cameras
연사: 박인규 교수 (인하대)
Abstract
In this talk, I address the depth estimation problem from two types of nonconventional images. First, I introduce a robust stereo matching algorithm for anaglyph images. Conventional stereo matching algorithms fail when handling anaglyph images that do not have similar intensities on their left and right images. To resolve this problem, we propose the novel data costs using local color prior and reverse intensity distribution factor for obtaining accurate depth maps. Second, I introduce a robust depth map estimation algorithm for 4D light field images. While conventional methods fail when handling noisy scene with occlusion, the proposed algorithm is more robust to occlusion and less sensitive to noise. Novel data costs using angular entropy metric and adaptive defocus response are introduced. Experimental results confirm that the proposed methods are robust and achieve high quality depth maps in various scenes.
Biography
In Kyu Park received his B.S., M.S., and Ph.D. degrees from Seoul National University in 1995, 1997, and 2001, respectively, all in electrical engineering and computer science. From September 2001 to March 2004, he was with Samsung Advanced Institute of Technology (SAIT). Since March 2004, he has been with the Department of Information and Communication Engineering, Inha University, where he is currently a full professor. From January 2007 to February 2008, he was an exchange scholar at Mitsubishi Electric Research Laboratories (MERL). From September 2014 to August 2015, he was a visiting associate professor at MIT Media Lab. His research interests include computer vision, computational photography, and GPGPU. He is a Senior Member of IEEE and a member of ACM.
Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition
연사: 김준모 교수 (KAIST)
Abstract
Temporal information has useful features for recognizing facial expressions. However, to manually design useful features requires a lot of effort. In this paper, to reduce this effort, a deep learning technique, which is regarded as a tool to automatically extract useful features from raw data, is adopted. Our deep network is based on two different models. The first deep network extracts temporal appearance features from image sequences, while the other deep network extracts temporal geometry features from temporal facial landmark points. These two models are combined using a new integration method in order to boost the performance of the facial expression recognition. Through several experiments, we show that the two models cooperate with each other. As a result, we achieve superior performance to other state-of- the-art methods in the CK+ and Oulu-CASIA databases. Furthermore, we show that our new integration method gives more accurate results than traditional methods, such as a weighted summation and a feature concatenation method.
Biography
Junmo Kim received the B.S. degree from Seoul National University, Seoul, Korea, in 1998, and the M.S. and Ph.D. degrees from the Massachusetts Institute of Technology (MIT), Cambridge, in 2000 and 2005, respectively. From 2005 to 2009, he was with the Samsung Advanced Institute of Technology (SAIT), Korea, as a Research Staff Member. He joined the faculty of KAIST in 2009, where he is currently an Assistant Professor of electrical engineering. His research interests are in image processing, computer vision, statistical signal processing, and information theory.
Visual Understanding of the Physical World for Interaction
연사: 임재환 교수 (University of Southern California)
Abstract
Recently, the computer vision community has made impressive progress on object recognition with deep learning approaches. However, for any visual system to interact with objects, it needs to understand much more than simply recognizing where the objects are. The goal of my research is to explore and solve physical understanding tasks for interaction – finding an object's pose in 3D, interpreting its physical interactions, and understanding its various states and transformations. Unfortunately, obtaining extensive annotated data for such tasks is often intractable, yet required by recent popular learning techniques.
In this talk, I take a step away from expensive, manually labeled datasets. Instead, I develop learning algorithms that are supervised through physical constraints combined with structured priors. I will first talk about how to build learning algorithms, including a deep learning framework (e.g., convolutional neural networks), that can utilize geometric information from 3D CAD models in combination with real-world statistics from photographs. Then, I will show how to use differentiable physics simulators to learn object properties simply by watching videos.
Biography
Joseph Lim will be an assistant professor at the University of Southern California starting Spring 2017, and is currently a postdoctoral researcher working with Professor Fei-Fei Li at Stanford University. He completed his PhD at Massachusetts Institute of Technology under the guidance of Professor Antonio Torralba, and also had a half-year long postdoc under Professor William Freeman. His research interests are in artificial intelligence, computer vision, and machine learning. He is particularly interested in deep learning, structure learning, and multi-domain data. Joseph graduated with BA in Computer Science from UC Berkeley, where he worked under Professor Jitendra Malik.
Advanced Patch-Based Image Synthesis
연사: 김민혁 교수 (KAIST)
Abstract
In this talk, I will present two advanced image synthesis methods: Laplacian patch-based image synthesis and multiview image synthesis. First, patch-based image synthesis has been enriched with global optimization on the image pyramid. Successively, the gradient-based synthesis has improved structural coherence and details. However, the gradient operator is directional and inconsistent and requires computing multiple operators. It also introduces a significantly heavy computational burden to solve the Poisson equation that of ten accompanies artifacts in non-integrable gradient fields. We propose a patch-based synthesis using a Laplacian pyramid to improve searching correspondence with enhanced awareness of edge structures. Contrary to the gradient operators, the Laplacian pyramid has the advantage of being isotropic in detecting changes to pro- vide more consistent performance in decomposing the base structure and the detailed localization. Furthermore, it does not require heavy computation as it employs approximation by the differences of Gaussians. We examine the potentials of the Laplacian pyramid for enhanced edge-aware correspondence search. We demonstrate the effectiveness of the Laplacian-based approach over the state-of-the-art patch-based image synthesis methods. Second, we present a multiview image completion method that provides geometric consistency among different views by propagating space structures. Since a user specifies the region to be completed in one of multiview photographs casually taken in a scene, the proposed method enables us to complete the set of photographs with geometric consistency by creating or removing structures on the specified region. The proposed method incorporates photographs to estimate dense depth maps. We initially complete color as well as depth from a view, and then facilitate two stages of structure propagation and structure-guided completion. Structure propagation optimizes space topology in the scene across photographs, while structure-guide completion enhances, and completes local image structure of both depth and color in multiple photographs with structural coherence by searching nearest neighbor fields in relevant views. We demonstrate the effectiveness of the proposed method in completing multiview images.
Biography
Min H. Kim is an assistant professor of computer science at KAIST, leading the Visual Computing Laboratory (VCLAB). Prior to KAIST, he received his PhD in computer science from University College London (UCL) in 2010 and also worked as a postdoctoral researcher at Yale University until 2012. In addition to serving on many conference program committees, he has been an associate editor of ACM Transactions on Graphics (TOG) since 2014.
Robustness in Computer Vision for Practical Applications: from 3D to Recognition
연사: 권인소 교수 (KAIST)
Abstract
컴퓨터비전 기술은 지난 40여년간 엄청난 발전을 거듭하였지만 성공적으로 실제 현장에 적용되어 그 가치를 인정 받은 경우는 극히 제한적이다. 최근 딥러닝 분야의 급속한 발전으로 많은 컴퓨터비전 분야의 난제들이 해결되고 있는 추세이지만, 여전히 실용화를 위한 단계에 도달하기 까지는 많은 어려움들이 존재하고 있다. 특히, 복잡한 환경, 디지털카메라의 한계, 조명변화나 환경변화 등에 대한 강인성이 확보되지 않은 것이 가장 어려운 문제들 중 하나로 평가되고 있다. 본 발표에서는 강인비전 연구에 대한 KAIST-RCV 실험실의 최근 연구성과들 중 실용화의 가능성이 보이는 다음 몇 가지 사례를 소개한다.
카메라를 이용한 3차원 정보 획득은 컴퓨터비전 분야에서 많이 연구된 주제이다. 특히 마이크로소프트에서 개발한 “Photo Tourism”은 인터넷 상에 공개된 다양한 영상을 이용하여 3차원정보 계산이 가능함을 보인 매우 훌륭한 사례이다. 그러나, 보통의 일반 사용자가 스스로 촬영한 제한된 수의 영상을 이용하여 정확도가 높은 3차원정보를 얻는 것은 쉽지 않은 형편이다. 이와 같은 촬영에 대한 한계를 극복하기 위하여, 보정되지 않은 카메라를 매우 작게 움직여서 영상을 획득하는 촬영방식을 채택하였다. 이 같은 작은 동작의 카메라가 제공하는 장점을 바탕으로 개발된 새로운 “Uncalibrated Structure-from-Small Motion” 방법론은 짧은 베이스라인에도 불구하고 매우 정확하게 3차원 정보 추출이 가능함을 보였다. 이 방법론을 최근 화제가 되고 있는 360o 카메라에 적용하여 그 강인성을 검증하였다.
기하학적 컴퓨터비전 문제 중에서도 SLAM은 로봇분야에서 오랜 기간 연구되어온 주제이지만, 지금까지 청소로봇의 자기위치인식에 사용된 예가 거의 유일한 상용화 사례이다. 본 연구실에서는 강인한 SLAM 기술을 개발하여 자동차의 위치를 실시간으로 인식하고 관련 영상정보를 공유하여 주변차량을 투명하게 만드는 기술개발에 성공하였다. 실제, 한국과 독일에서 진행된 실제 도로에서의 테스트를 통하여 그 강인성을 보였으며, 향 후 상용화를 통하여 자동차 사고를 줄이는데 일조할 것으로 기대된다.
물체인식은 ILSVRC 대회에서 최근 딥러닝 기반의 방법론들이 엄청난 인식률로 성공을 거두면서 새로운 전기를 맞고 있다. 특히, KAIST-RCV가 주도한 “Lunit-KAIST” 팀은 AttentionNet기반의 새로운 딥러닝 아키텍처를 개발하여 2015년 대회에서 “CLS+LOC”분과에서 참가 70개팀 중 5등이라는 대단한 성과를 거두었다. 본 발표에서는 AttentionNet의 특성과 원리를 소개하고, 다양한 인식문제에 대한 적용결과도 함께 소개한다.
Biography
Professor Kweon received the B.S. and the M.S. degrees in Mechanical Design and Production Engineering from Seoul National University, Korea, in 1981 and 1983, respectively, and the Ph.D. degree in Robotics from the Robotics Institute at Carnegie Mellon University in 1990. He worked for Toshiba R&D Center, Japan, and joined KAIST in 1992. He is a KEPCO Chair Professor of School of Electrical Engineering (EE) and the director for the National Core Research Center – P3 DigiCar Center at KAIST.
Professor Kweon's research interests include computer vision and robotics. He has co-authored several books, including “Metric Invariants for Camera Calibration,” and more than 300 technical papers. He served as a Founding Associate-Editor-in-Chief for “International Journal of Computer Vision and Applications”, and has been an Editorial Board Member for “International Journal of Computer Vision” since 2005 for ten years.
Professor Kweon is a member of many computer vision and robotics conference program committees and has been a program co-chair for several conferences and workshops. He was a General co-chair of the 2012 Asian Conference on Computer Vision (ACCV) Conference and is a Program Chair of ICCV’2019.
Professor Kweon received several awards from the international conferences, including “The Best Student Paper Runnerup Award in the IEEE-CVPR’2009” and “The IEEE-CSVT Best Paper Award in 2014”.
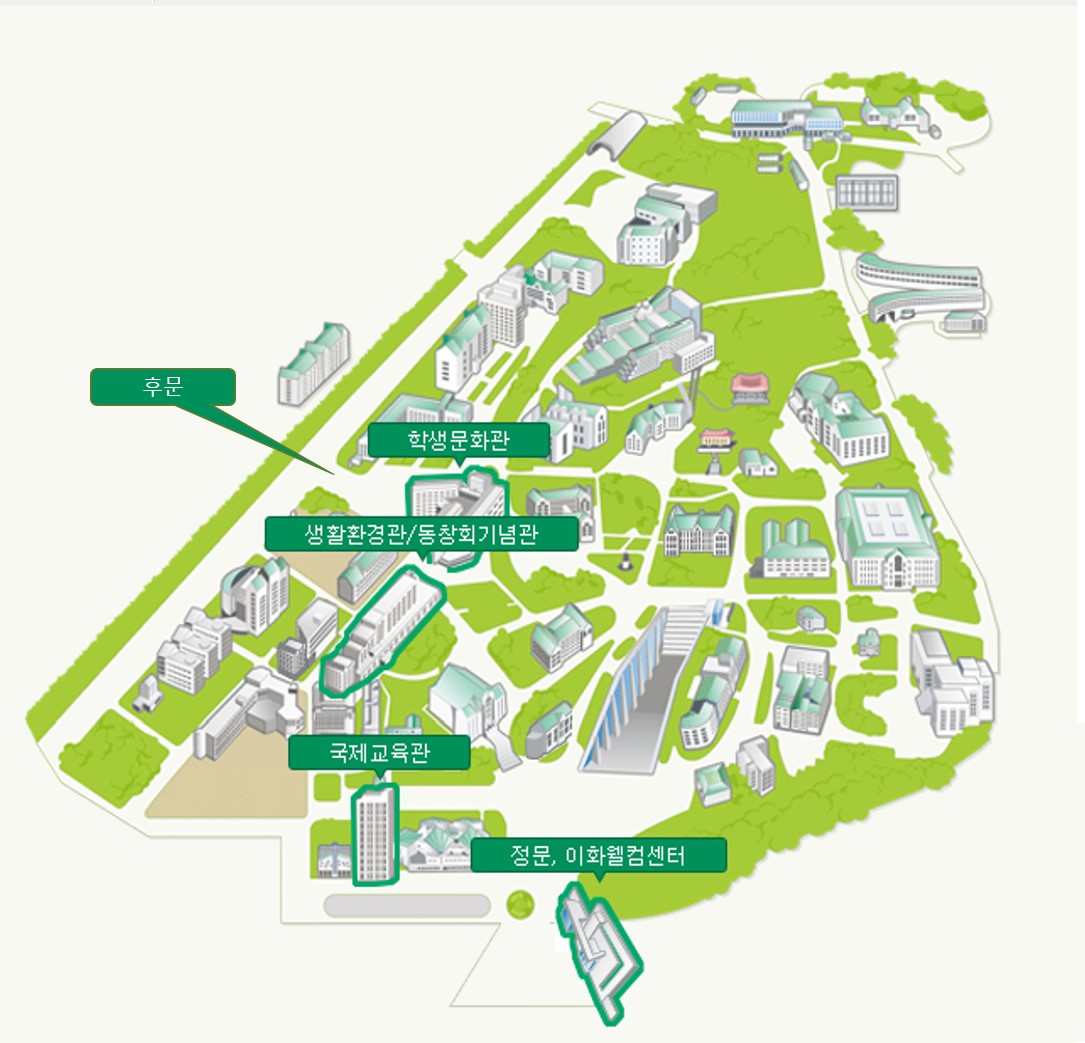
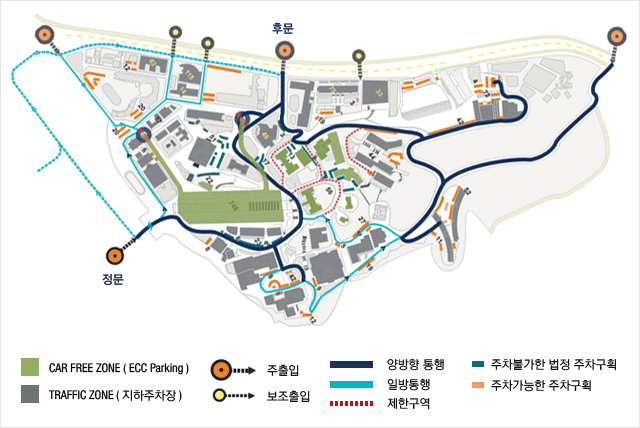
장소 안내
[Google Map] [ Naver Map] [ Daum Map] 주차안내[주차안내] : 지하주차장 입구는 학생 문화관 맞은 편입니다.
주차장은 ECC지하 5/6층 (B5/B6)입니다. 1번 elevator를 타고 B2 에서 내려서 건물 밖으로 나오면 Gate 11번입니다. 여기에서 왼쪽에 보이는 14층 건물이 국제교육관이고 그 건물 오른쪽에 학술대회 장소인 LG 컨벤션 홀로 내려가는 계단이 있습니다. |
등록 안내사전 등록 : 2016. 06. 24. (Fri) - 07. 18. (Mon)
현장 등록 : 2016. 07. 21. (Thr) 12:00 - 07. 22 (Fri) 15:00
점심식사 : 22일 학생식당 식권제공 주차 : 종일권은 4000원, 4시간권은 2,000원이고 등록 데스크에서 구입하실 수 있습니다. 등록문의 연락처 : 이화여대 전자과 영상연구실
|